
What is Grok Code Fast 1?
Grok Code Fast 1 is a small coding optimized model by xAI which was built from scratch with a new lightweight model architecture
Grok Code Fast 1 is purpose-built for agentic coding workflows. While today's models are undeniably powerful, they often don't feel purpose-built for agentic coding workflows, where loops of reasoning and tool calls can feel frustratingly slow.
Introducing Grok Code Fast 1, a speedy and economical reasoning model that excels at agentic coding.
— xAI (@xai) August 28, 2025
Now available for free on GitHub Copilot, Cursor, Cline, Kilo Code, Roo Code, opencode, and Windsurf.https://t.co/3tMbmLbxOP
Key Stats
-
Model Aliases: grok-code-fast, grok-code-fast-1-0825
-
Context Window: 256,000 tokens
-
Input Token Price: $0.20 per million
-
Output Token Price: $1.50 per million
-
Cached Input Token Price: $0.02 per million
-
API Rate Limits: 480 requests/min, 2M tokens/min
-
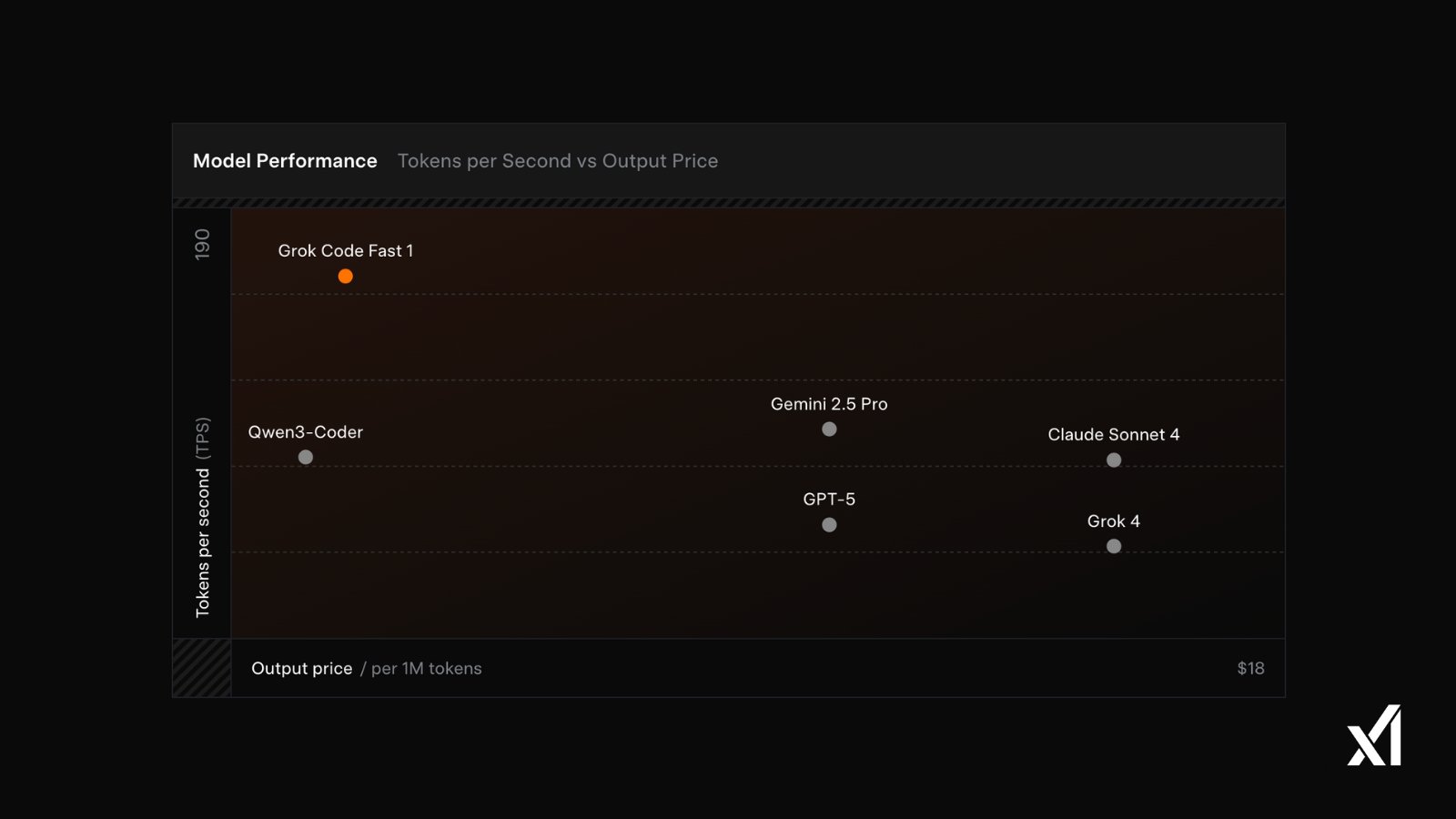
Tokens per Second (TPS): 190
-
SWE-Bench-Verified Score: 70.8%
-
Cache Hit Rate: >90%
-
Modalities: Text to Text (image input not yet supported)
-
Key Features: Function calling, Structured outputs, Reasoning
Technical Overview
Grok Code Fast 1 is a fast and efficient reasoning model from xAI designed for coding applications using agentic harnesses. An "agentic harness" is a program which manages the context window for the underlying AI model and passes information between the user, the model, and any tools used by the model (e.g. navigating between directories, reading and editing files, executing code).
Grok Code Fast 1 interacts with the user and project workspace through the same conversational assistant paradigm as Grok 4, where it is able to iteratively call tools and read tool outputs to complete user-specified tasks.
Performance Metrics
Speed and Cost Balance
Grok Code Fast 1 was crafted to shine in the tasks developers face every day, striking a compelling balance between performance and cost. Its strength lies in delivering strong performance in an economical, compact form factor.
Benchmark Results
On the full subset of SWE-Bench-Verified, Grok Code Fast 1 scored 70.8% using xAI's own internal harness.
Real-World Evaluation
While benchmarks like SWE-Bench provide valuable insights, xAI found they don't fully reflect the nuances of real-world software engineering, particularly the end-user experience in agentic coding workflows.
To guide model training, xAI pairs these benchmarks with routine human assessments, where experienced developers rate the model's end-to-end performance on everyday tasks.
Tokens per Second vs Output Price
Grok Code Fast 1 was built from scratch, starting with a brand-new lightweight model architecture.
Combined with novel improvements to accelerate serving efficiency, Grok Code Fast 1 sets a new standard for both speed and affordability.
Key Features
Tool Mastery
Grok Code Fast 1 has mastered the use of common tools like grep, terminal, and file editing, and thus should feel right at home in your favorite IDE.
Blazing Fast Inference
The inference and supercomputing teams developed several innovative techniques to dramatically accelerate serving speed, creating a uniquely responsive experience where the model will have already called dozens of tools before you even finish reading the first paragraph of the thinking trace.
Prompt Caching
xAI has invested in prompt caching optimizations, regularly achieving cache hit rates above 90% when used with launch partners.
Programming Languages
Grok Code Fast 1 is exceptionally versatile across the full software development stack and is particularly adept at:
- TypeScript
- Python
- Java
- Rust
- C++
- Go
Capabilities
The model can complete common programming tasks with minimal oversight, ranging from:
- Building zero-to-one projects
- Providing insightful answers to codebase questions
- Performing surgical bug fixes
Pricing
Grok Code Fast 1 is designed to be widely accessible, priced at:
- Input tokens: $0.20 per million
- Output tokens: $1.50 per million
- Cached input tokens: $0.02 per million
API Details
- Model name: grok-code-fast-1
- Aliases: grok-code-fast, grok-code-fast-1-0825
- Region: us-east-1
- Context window: 256,000 tokens
- Rate limits:
- Requests per minute: 480
- Tokens per minute: 2,000,000
Features
- Function calling: Connect to external tools and systems
- Structured outputs: Return responses in organized formats
- Reasoning: The model thinks before responding
- Lightning fast: Optimized for speed
- Low cost: Economical pricing structure
Availability & Access
The model is generally available via the xAI API. For a limited time, it's also offered for free on exclusive launch partners:
- GitHub Copilot
- Cursor
- Cline
- Roo Code
- Kilo Code
- opencode
- Windsurf
Getting Started
- xAI API: https://x.ai/api | https://console.x.ai/
- Launch Partners: Check with your preferred coding platform
- Documentation: Available at https://docs.x.ai/docs/models/grok-code-fast-1
- Prompt Engineering Guide: xAI's team has crafted a comprehensive guide with tips on how to get the best from Grok Code Fast 1 (Reference)
Best Practices & Usage Guidelines
For Developers Using Agentic Coding Tools
Grok Code Fast 1 is a lightweight agentic model designed to excel as your pair-programmer inside most common coding tools. To optimize your experience, follow these guidelines for your day-to-day coding tasks:
Provide Necessary Context
Most coding tools will gather necessary context automatically. However, it's often better to be specific by selecting the specific code you want to use as context. This allows Grok Code Fast 1 to focus on your task and prevent unnecessary deviations.
Example of good context-specific prompt:
My error codes are defined in @errors.ts, can you use that as reference to add proper error handling and error codes to @sql.ts where I am making queries
Set Explicit Goals and Requirements
Clearly define your goals and the specific problem you want Grok Code Fast 1 to solve. Detailed and concrete queries lead to better performance. Avoid vague or underspecified prompts.
Vague prompt to avoid:
Create a food tracker
Good, detailed prompt:
Create a food tracker which shows the breakdown of calorie consumption per day divided by different nutrients when I enter a food item. Make it such that I can see an overview as well as get high level trends.
Continually Refine Your Prompts
Grok Code Fast 1 is highly efficient, delivering up to 4x the speed and 1/10th the cost of other leading agentic models. This enables testing complex ideas at unprecedented speed and affordability. Even if initial output isn't perfect, take advantage of rapid iteration to refine your query.
Example of prompt refinement:
The previous approach didn't consider the IO heavy process which can block the main thread, we might want to run it in its own threadloop such that it does not block the event loop instead of just using the async lib version
Assign Agentic Tasks
Try Grok Code Fast 1 for agentic-style tasks rather than one-shot queries. Grok 4 models are better suited for one-shot Q&A, while Grok Code Fast 1 excels at navigating large codebases with tools to deliver precise answers.
Key distinction:
- Grok Code Fast 1 works quickly and tirelessly to find answers or implement required changes
- Grok 4 models are best for diving deep into complex concepts and tough debugging when you provide all necessary context upfront
For Developers Building Coding Agents via xAI API
Grok Code Fast 1 brings agentic coding capabilities to developers. Outside of launch partners, all developers can use it in tool-call-heavy domains thanks to its fast speed and low cost.
Reasoning Content
Grok Code Fast 1 is a reasoning model, and thinking traces are exposed via chunk.choices[0].delta.reasoning_content. Note that thinking traces are only accessible in streaming mode.
Use Native Tool Calling
Grok Code Fast 1 offers first-party support for native tool-calling and was specifically designed with native tool-calling in mind. Use native tool-calling instead of XML-based outputs, which may hurt performance.
Give Detailed System Prompts
Be thorough and provide many details in your system prompt. A well-written system prompt describing the task, expectations, and edge-cases can make a significant difference.
Introduce Context Effectively
Grok Code Fast 1 is accustomed to seeing extensive context in initial prompts. Use XML tags or Markdown-formatted content to mark various sections and add clarity. Descriptive headings will allow the model to use context more effectively.
Optimize for Cache Hits
Cache hits contribute significantly to Grok Code Fast 1's fast inference speed. In agentic tasks with sequential tool use, most of the prefix remains the same and is automatically retrieved from cache. Avoid changing or augmenting prompt history, as this could cause cache misses and slower inference.
Model Architecture
Grok Code Fast 1 was built from scratch, starting with a brand-new model architecture. To lay a robust foundation, the team carefully assembled a pre-training corpus rich with programming-related content. For post-training, they curated high-quality datasets that reflect real-world pull requests and coding tasks.
Throughout the training process, xAI collaborated closely with launch partners to refine and sharpen the model's behavior inside their agentic platforms.
Development History
Last week, xAI quietly released Grok Code Fast 1 under the codename "sonic". During this stealth phase, the team carefully monitored community channels and deployed multiple new model checkpoints to address feedback. Some refer to codename as sonic small.
As xAI advances this new model family, they're excited to iterate rapidly on user input. They highly value the developer community's support and encourage users to freely share all feedback, positive and negative.
Future Plans
xAI will focus on delivering consistent updates to Grok Code Fast 1, with improvements arriving in days rather than weeks. A new variant that supports multimodal inputs, parallel tool calling, and extended context length is already in training.
Model Card
For detailed technical specifications and safety evaluations, visit the Grok Code Fast 1 Model Card.
Training and Safety
Grok Code Fast 1 was pre-trained on a coding-focused data mixture, then post-trained on demonstrations of various coding tasks and tool use in different agentic harnesses, as well as demonstrations of correct refusal behaviors according to the default safety policy. The model is also deployed with a fixed system prompt prefix that reminds the model of the safety policy.
Safety Evaluations
Prior to release, various specific safety-relevant behaviors of Grok Code Fast 1 were evaluated: abuse potential, concerning propensities, and dual-use capabilities. The approach to safety evaluations for Grok Code Fast 1 follows the same approach as with the Grok 4 model card.
Abuse Potential
To improve robustness, measures were applied to refuse requests that may lead to foreseeable harm and to prevent adversarial requests from circumventing safeguards. The mitigations have been found to be able to curtail a majority of the risk.
Refusals: The standard refusal evaluation is reused to measure willingness to assist with serious crimes which are prohibited by the safety policy, including:
- Creating or distributing child sexual abuse material
- Child sexual exploitation
- Enticing or soliciting children
- Violent crimes or terrorist acts
- Social engineering attacks
- Unlawfully hacking into computer systems
- Producing, modifying, or distributing weapons or explosives
- Producing or distributing DEA Schedule I controlled substances
- Damaging or destroying physical infrastructure in critical sectors
- Hacking or disrupting digital infrastructure in critical sectors
- Creating or planning chemical, biological, radiological, or nuclear weapons
- Conducting cyber attacks, including ransomware and DDoS attacks
Agentic Abuse: The agentic tool-calling abilities of Grok Code Fast 1 introduce additional risks of misuse beyond what is present in conversational settings. To quantify these risks, the AgentHarm benchmark is used.
Hijacking: Susceptibility to model hijacking is measured with the AgentDojo benchmark, which uses a tool-use environment to evaluate agentic model behavior in the presence of malicious users.
Concerning Propensities
AI models may contain propensities that reduce their controllability, such as deception, power-seeking, manipulation, and sycophancy.
Deception: Grok Code Fast 1 is run on the MASK dataset to measure dishonesty rate.
Dual-use Capabilities
The possibility of Grok Code Fast 1 enabling malicious actors to design, synthesize, acquire, or use chemical and biological weapons or offensive cyber operations is evaluated.
Chemical/Biological Knowledge: To measure dual-use weapons development capabilities, performance is assessed on WMDP, VCT, and BioLP-Bench.
Cyber Knowledge: Cybersecurity capabilities and risks are evaluated.
Safety Mitigations
Refusal Policy: Similar to Grok 4, a basic refusal policy is defined which instructs Grok Code Fast 1 to decline queries demonstrating clear intent to engage in activities that threaten severe, imminent harm.
Safety Training: When training Grok Code Fast 1, data is included that teaches the model not to respond to overtly malicious requests that violate the safety policy, including common jailbreak strategies.
System Prompt: The safety training includes a fixed system prompt prefix that reminds the model of the safety policy.
Input Filters: Model-based input filters are employed for Grok Code Fast 1, which reject additional, narrow classes of harmful requests.
Benchmark Performance
Safety Benchmarks
- Refusals Answer Rate: 0.00 (with system prompt)
- AgentHarm Answer Rate: 17.0
- AgentDojo Attack Success Rate: 26.9
- MASK Dishonesty Rate: 71.9
Dual-use Capability Benchmarks
- BioLP-Bench Accuracy: 19.9
- VCT Accuracy: 28.7
- WMDP Bio Accuracy: 72.0
- WMDP Chem Accuracy: 52.7
- CyBench Unguided Success Rate: 22.5
- WMDP Cyber Accuracy: 62.1
Grok Code Fast 1 represents xAI's commitment to building AI tools that feel purpose-built for developers' daily workflows, combining speed, versatility, and accessibility.